Parameter Efficient Fine-tuning (PEFT)
updates only a small subset of parameters. This helps prevent catastrophic forgetting.
- Selective:
- select subset of initial LLM parameters to fine-tune
- Re-parameterization
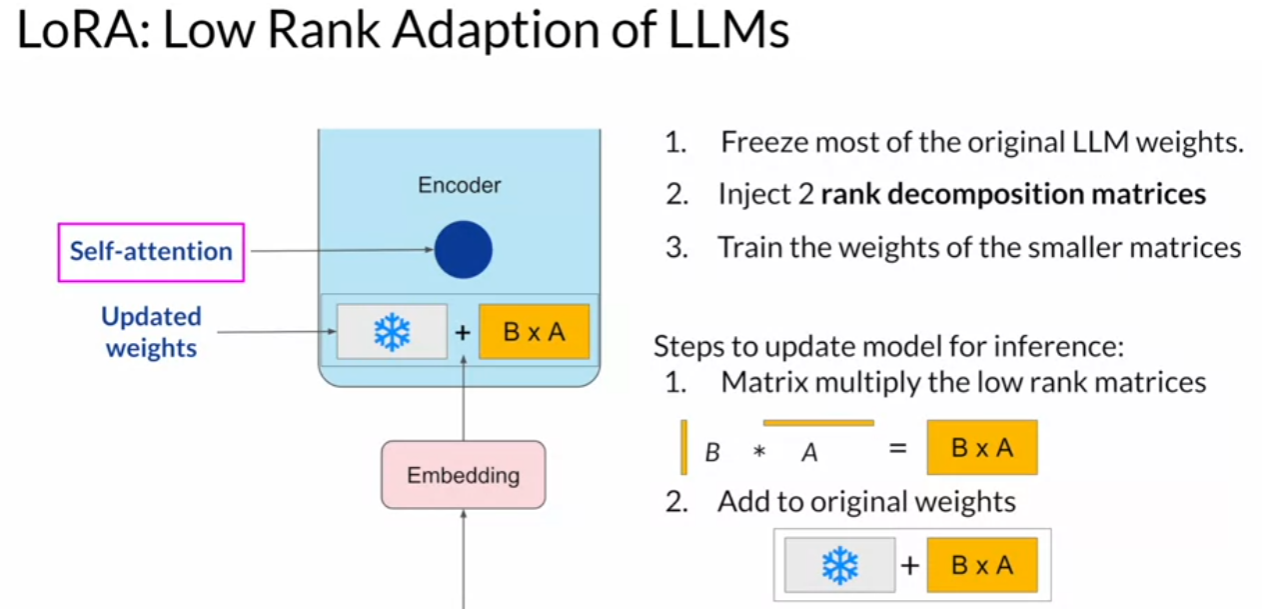
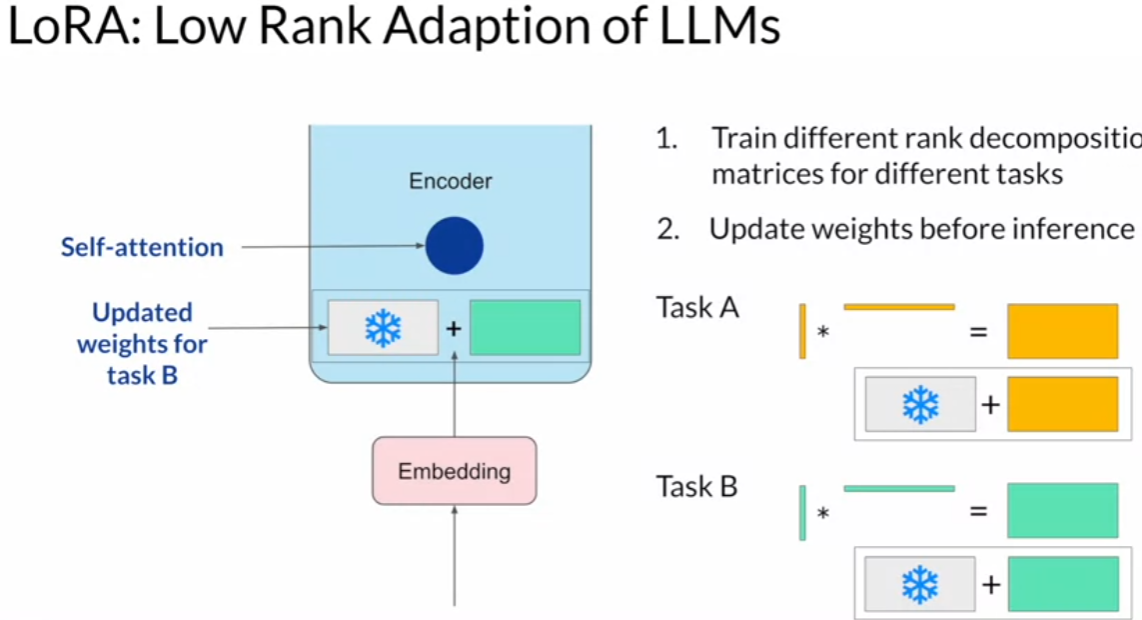
- re-parameterize model weights using a low-rank representation (LoRA)
- Additive
- add trainable layers or parameters to model
- adapters
- soft prompts (prompt tuning)
- add trainable layers or parameters to model
Low Rank Adaption of LLMs (LoRA)