Transformers
Learns the relevance of each word to each other word in a sentence.
Simplified architecture
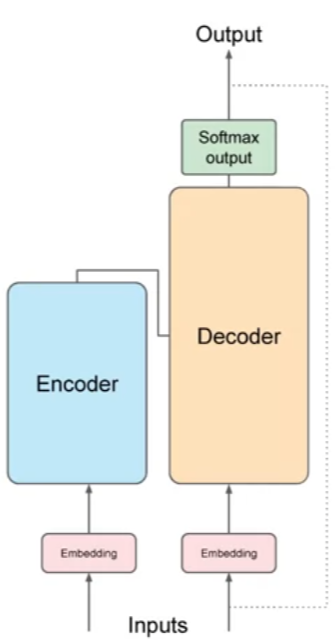
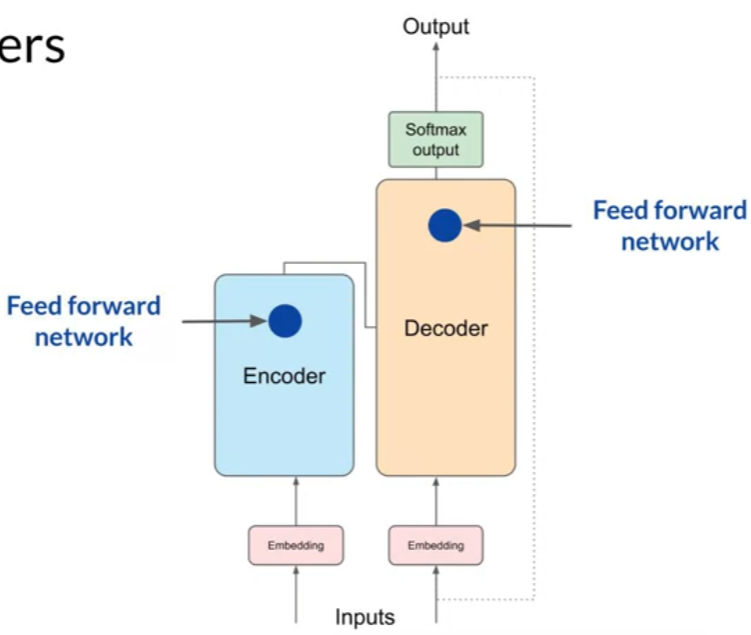
Encoder
- Encodes inputs (“prompts”) with contextual understanding and produces one vector per input token.
- The data that leaves the encoder is a deep representation of the structure and meaning of the input sequence
- It consists of multiple identical layers, each with two main components: Multi-Head Self-Attention Mechanism and Position-wise Feedforward Networks.
Decoder
- Accepts input tokens and generates new tokens in a loop.
- Like the encoder, the decoder consists of multiple identical layers, but with additional components: Multi-Head Self-Attention Mechanism, Multi-Head Attention over the encoder’s output, and Position-wise Feedforward Networks.
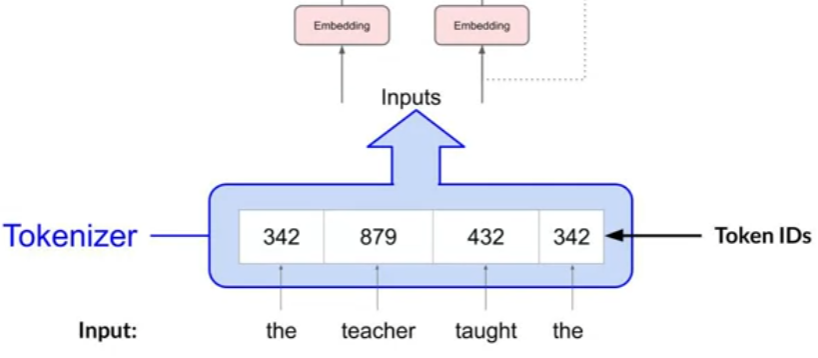
a trainable vector embedding space, a high-dimensional space where each token is represented as a vector and occupies a unique location within that space.
Each token ID in the vocabulary is matched to a multi-dimensional vector,
these vectors learn to encode the meaning and context of individual tokens in the input sequence.
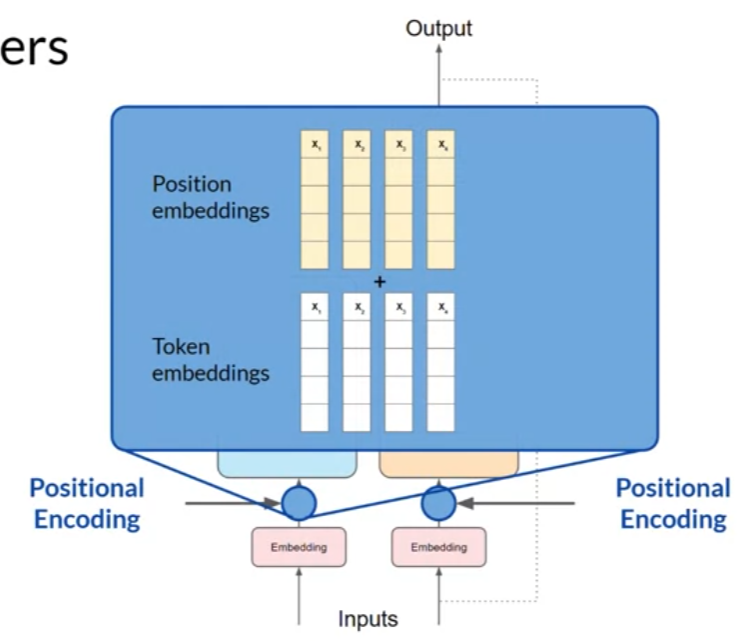 by adding the positional encoding, you preserve the information about the word order and don’t lose the relevance of the position of the word in the sentence.
by adding the positional encoding, you preserve the information about the word order and don’t lose the relevance of the position of the word in the sentence.
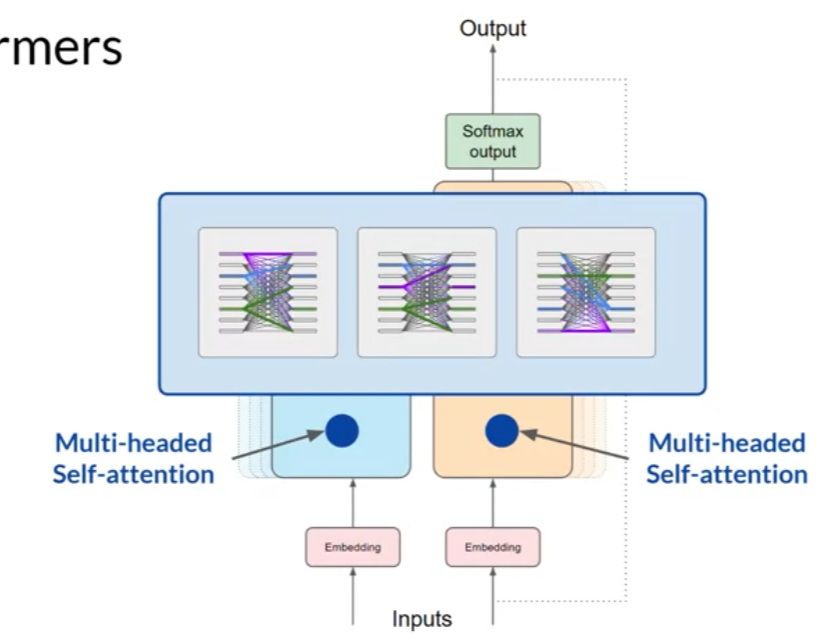 the model analyzes the relationships between the tokens in your input sequence.
the model analyzes the relationships between the tokens in your input sequence.
this allows the model to attend to different parts of the input sequence to better capture the contextual dependencies between the words.
The self-attention weights that are learned during training and stored in these layers reflect the importance of each word in that input sequence to all other words in the sequence.
multiple sets of self-attention weights or heads are learned in parallel independently of each other.
each self-attention head will learn a different aspect of language.
- For example, one head may see the relationship between the people entities in our sentence.
- Whilst another head may focus on the activity of the sentence.
- Whilst yet another head may focus on some other properties such as if the words rhyme.
the output is processed through a fully-connected feed-forward network.
The output of this layer is a vector of logits proportional to the probability score for each and every token in the tokenizer dictionary.
You can then pass these logits to a final softmax layer, where they are normalized into a probability score for each word. This output includes a probability for every single word in the vocabulary,
Detailed architecture
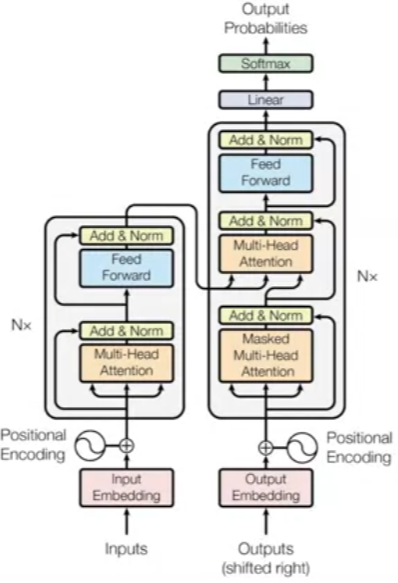
Transformer models
Encoder-only model
Example: BERT (Bidirectional Encoder Representations from Transformers)
Architecture: BERT is an example of an encoder-only model. It utilizes a multi-layer bidirectional Transformer encoder.
Task: Pre-trained on large corpora for various language understanding tasks, such as question answering, natural language inference, and more. It captures contextualized representations of words in a bidirectional manner.
Usage: Given a sentence or text, BERT can be used to extract features or embeddings for downstream tasks without the need for a decoder.
Decoder-Only Model:
Example: GPT, BLOOM, Jurassic, LLaMA
Architecture: GPT is an example of a decoder-only model.
It uses a stack of Transformer decoders. Task: Pre-trained on a diverse range of internet text to generate coherent and contextually relevant text.
Usage: Given a prompt or an initial sequence, GPT can generate a continuation, making it useful for tasks like text completion, summarization, and creative text generation.
Encoder-Decoder Model:
Example: Transformer (for machine translation), BART, T5
Architecture: The original Transformer model is an encoder-decoder architecture.
Task: Trained for sequence-to-sequence tasks like machine translation. The encoder processes the source language, and the decoder generates the target language.
Usage: Given a sentence in one language, the encoder processes it into a fixed-size context representation. The decoder then generates the equivalent sentence in another language.
Prompt Engineering
-
Prompt: the text that you feed into the model
-
Inference: the act of generating text
-
Completion: the output text

Generative Config
Greedy vs random sampling

Top-k and Top-p

Temperature

Generative AI Lifecycle
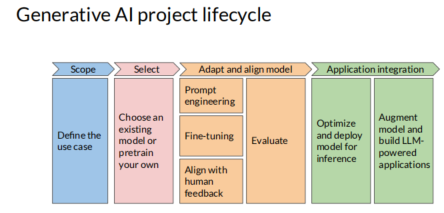
LLM pre-training
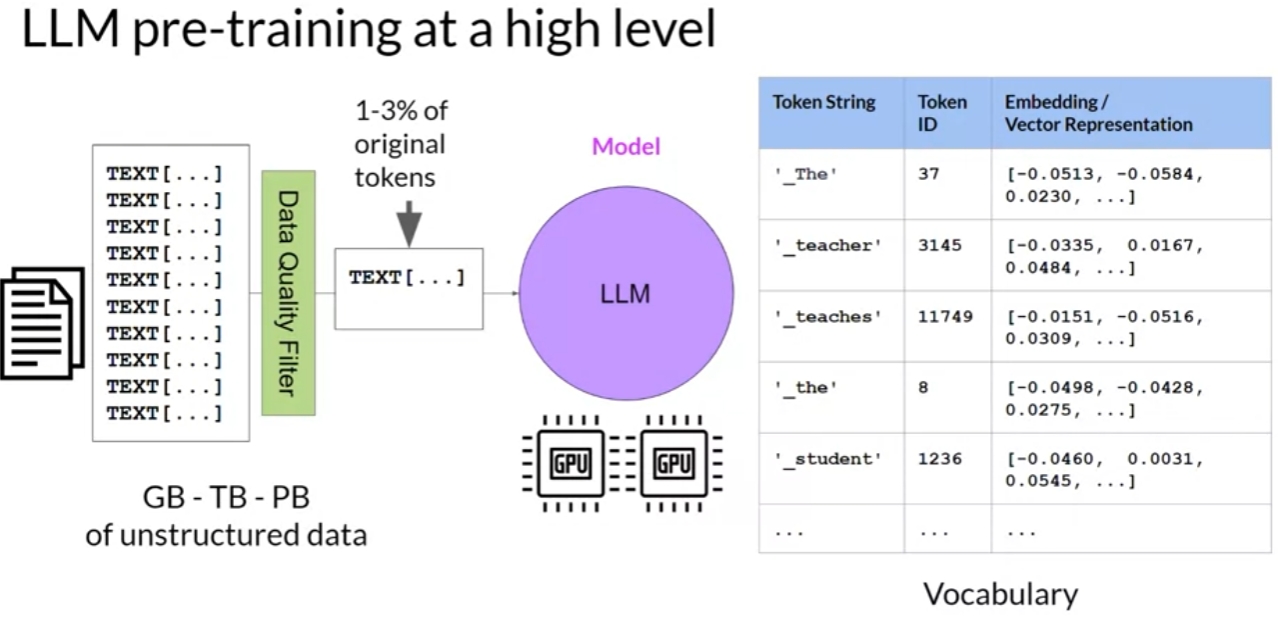
self-supervised learning step.
the model internalizes the patterns and structures present in the language.
These patterns then enable the model to complete its training objective, which depends on the architecture of the model.
the model weights get updated to minimize the loss of the training objective. The encoder generates an embedding or vector representation for each token.
when you scrape training data from public sites such as the Internet, you often need to process the data to increase quality, address bias, and remove other harmful content. As a result of this data quality curation, often only 1-3% of tokens are used for pre-training.
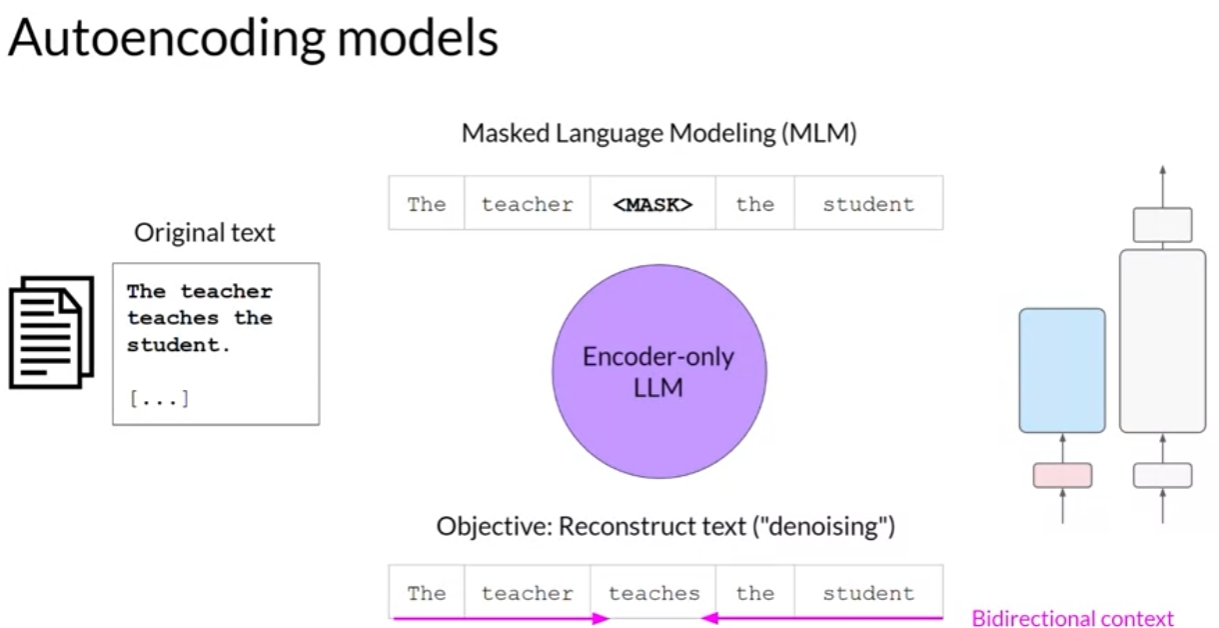
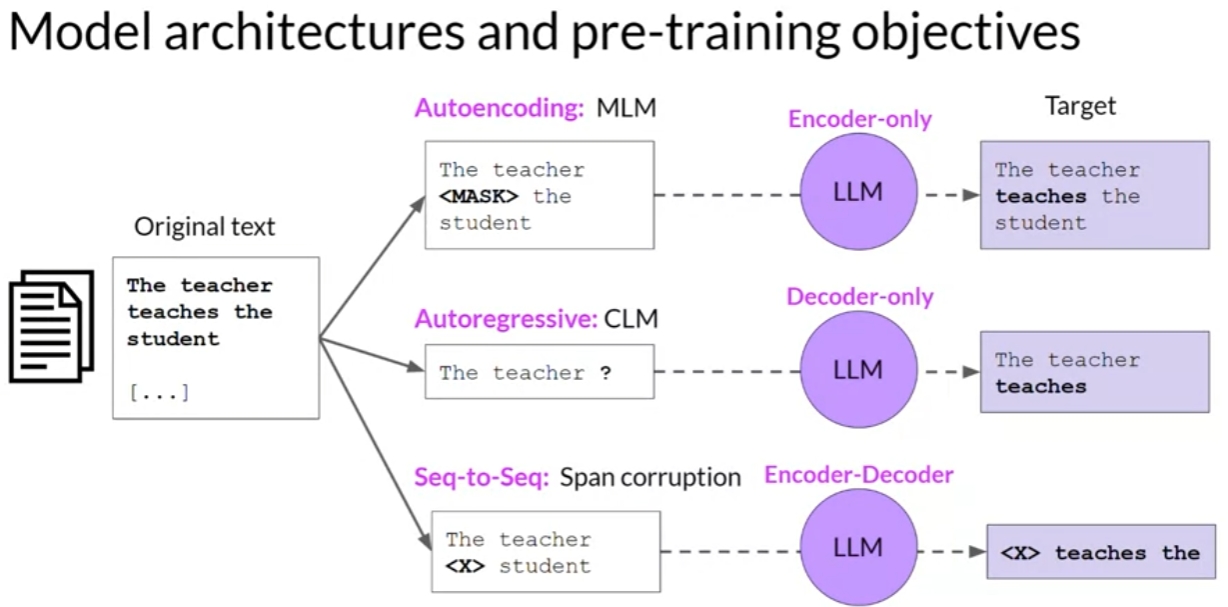
Encoder-only model
Masked Language Modeling (MLM)
use cases:
- sentiment analysis
- named entity recognition
- word classification
examples:
- BERT
- ROBERTA
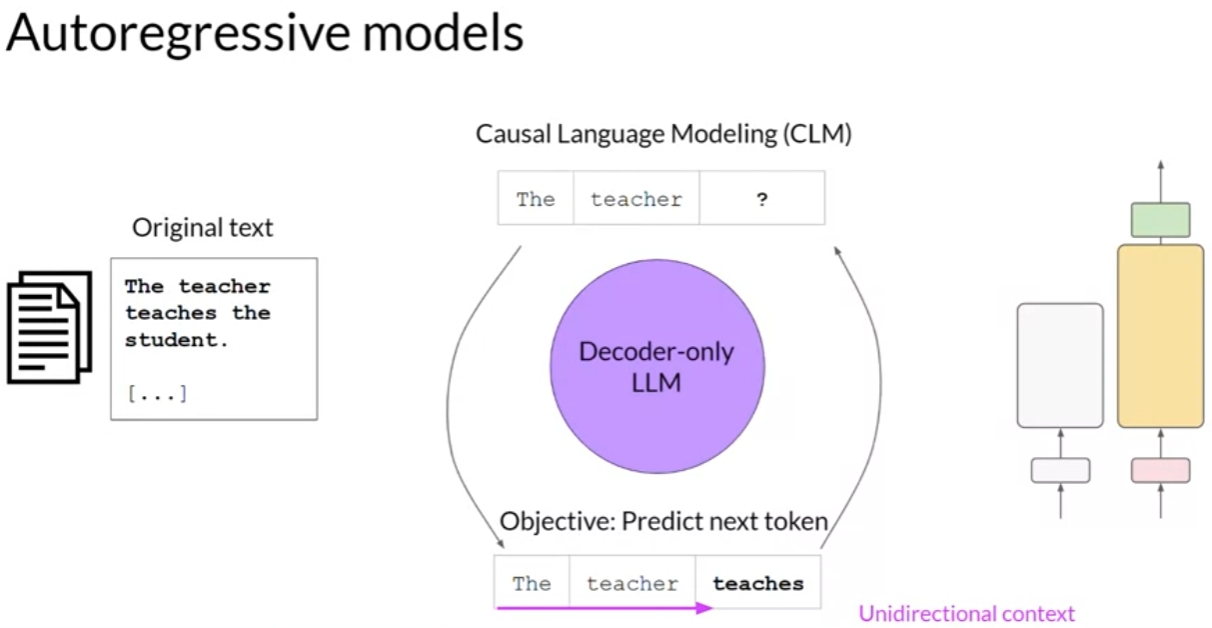
Decoder-only model
Causal Language Modeling (CLM)
use cases:
- text generation
- other emergent behavior
- depends on model size
examples:
- GPT
- BLOOM
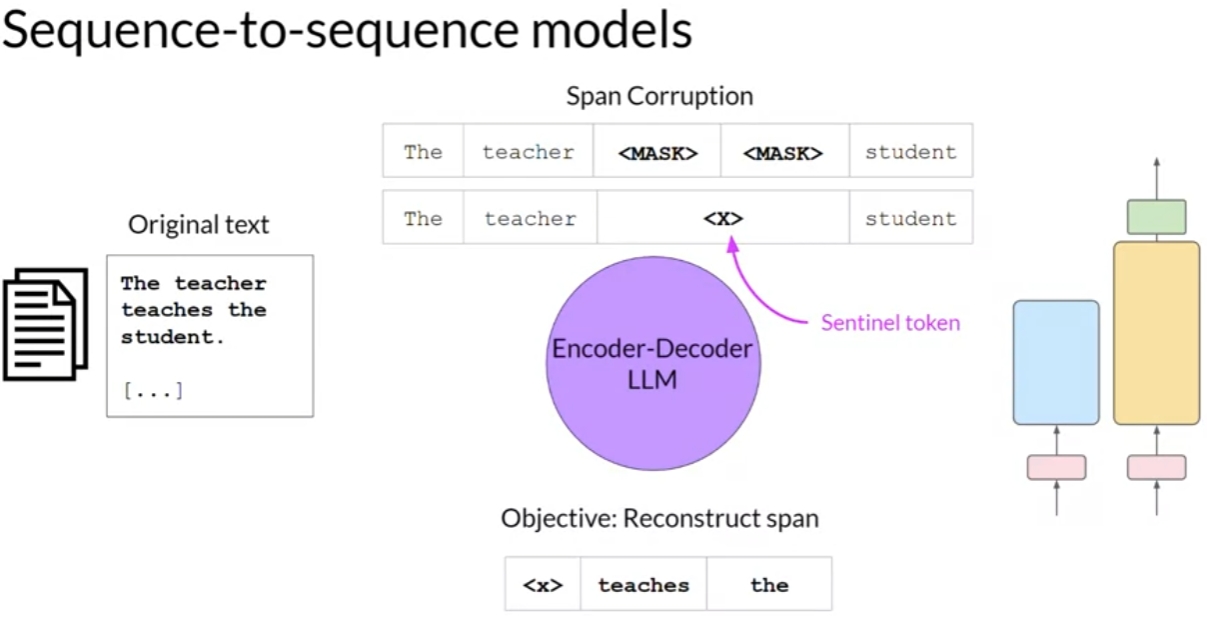
Encoder-Decoder model
use cases:
- translation
- text summarization
- question answering
examples:
- T5
- BART
Summary
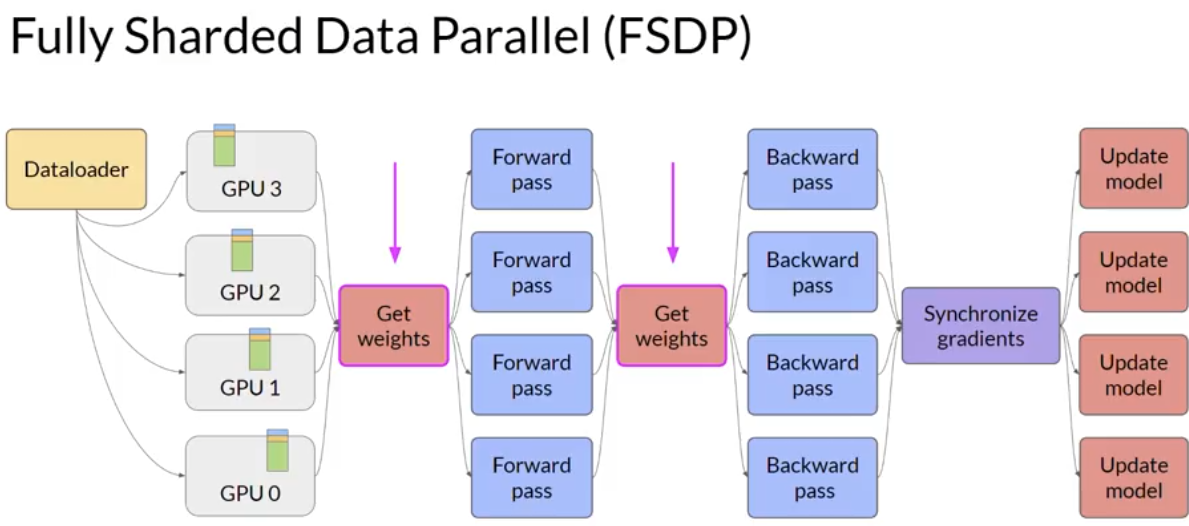
Multi-GPU compute strategies
zeRO
Pretrain Model for Domain adaptation
BloombergGPT: A Large Language Model for Finance.



